.tar
解包: tar xvf FileName.tar
打包:tar cvf FileName.tar DirName
(注:tar是打包,不是压缩!)
---------------------------------------------
.gz
解压1:gunzip FileName.gz
解压2:gzip -d FileName.gz
压缩:gzip FileName
.tar.gz 和 .tgz
解压:tar zxvf FileName.tar.gz
压缩:tar zcvf FileName.tar.gz DirName
---------------------------------------------
.bz2
解压1:bzip2 -d FileName.bz2
解压2:bunzip2 FileName.bz2
压缩: bzip2 -z FileName
.tar.bz2
解压:tar jxvf FileName.tar.bz2
压缩:tar jcvf FileName.tar.bz2 DirName
---------------------------------------------
.bz
解压1:bzip2 -d FileName.bz
解压2:bunzip2 FileName.bz
压缩:未知
.tar.bz
解压:tar jxvf FileName.tar.bz
压缩:未知
---------------------------------------------
.Z
解压:uncompress FileName.Z
压缩:compress FileName
.tar.Z
解压:tar Zxvf FileName.tar.Z
压缩:tar Zcvf FileName.tar.Z DirName
---------------------------------------------
.zip
解压:unzip FileName.zip
压缩:zip FileName.zip DirName
---------------------------------------------
.rar
解压:rar a FileName.rar
压缩:r ar e FileName.rar
rar请到:http://www.rarsoft.com/download.htm 下载!
解压后请将rar_static拷贝到/usr/bin目录(其他由$PATH环境变量指定的目录也可以):
[root@www2 tmp]# cp rar_static /usr/bin/rar
---------------------------------------------
.lha
解压:lha -e FileName.lha
压缩:lha -a FileName.lha FileName
lha请到:http://www.infor.kanazawa-it.ac.jp/~ishii/lhaunix/下载!
>解压后请将lha拷贝到/usr/bin目录(其他由$PATH环境变量指定的目录也可以):
[root@www2 tmp]# cp lha /usr/bin/
---------------------------------------------
.rpm
解包:rpm2cpio FileName.rpm | cpio -div
---------------------------------------------
.deb
解包:ar p FileName.deb data.tar.gz | tar zxf -
---------------------------------------------
如果知道所要使用的压缩解压命令,但是不知道命令的参数与用法,可以使用命令 -help的方法获取参数与使用方法信息等.
2009年4月22日星期三
2009年3月31日星期二
(转)lucene 的score详解
转自:http://www.cppblog.com/javenstudio/articles/23424.html
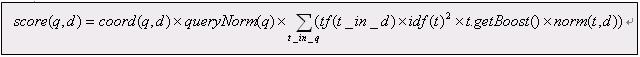
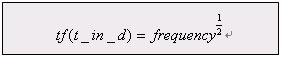
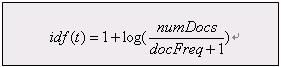



查询q相对于文档d的分数与在文档和查询向量(query vectors)之间的余弦距离(cosing-distance)或者点乘积(dot-product)有关系(correlates to),文档和查询向量存于一个信息检索(Information Retrieval)的向量空间模型(Vector Space Model (VSM))之中。一篇文档的向量与查询向量越接近(closer to),它的得分也越高(scored higher),这个分数按如下公式计算:
其中:
1. tf(t in d) 与term的出现次数(frequency)有关系(correlate to),定义为(defined as)term t在当前算分(currently scored)的文档d中出现(appear in)的次数(number of times)。对一个给定(gived)的term,那些出现此term的次数越多(more occurences)的文档将获得越高的分数(higher score)。缺省的tf(t in d)算法实现在DefaultSimilarity类中,公式如下:
2. idf(t) 代表(stand for)反转文档频率(Inverse Document Frequency)。这个分数与反转(inverse of)的docFreq(出现过term t的文档数目)有关系。这个分数的意义是越不常出现(rarer)的term将为最后的总分贡献(contribution)更多的分数。缺省idff(t in d)算法实现在DefaultSimilarity类中,公式如下:
3. coord(q,d) 是一个评分因子,基于(based on)有多少个查询terms在特定的文档(specified document)中被找到。通常(typically),一篇包含了越多的查询terms的文档将比另一篇包含更少查询terms的文档获得更高的分数。这是一个搜索时的因子(search time factor)是在搜索的时候起作用(in effect at search time),它在Similarity对象的coord(q,d)函数中计算。
4. queryNorm(q) 是一个修正因子(normalizing factor),用来使不同查询间的分数更可比较(comparable)。这个因子不影响文档的排名(ranking)(因为搜索排好序的文档(ranked document)会增加(multiplied)相同的因数(same factor)),更确切地说只是(but rather just)为了尝试(attempt to)使得不同查询条件(甚至不同索引(different indexes))之间更可比较性。这是一个搜索时的因子是在搜索的时候起作用,由Similarity对象计算。缺省queryNorm(q)算法实现在DefaultSimilarity类中,公式如下:
sumOfSquaredWeights(查询的terms)是由查询Weight对象计算的,例如一个布尔(boolean)条件查询的计算公式为:
5. t.getBoost() 是一个搜索时(search time)的代表查询q中的term t的boost数值,具体指定在(as specified in)查询的文本中(参见查询语法),或者由应用程序调用setBoost()来指定。需要注意的是实际上(really)没有一个直接(direct)的API来访问(accessing)一个多个term的查询(multi term query)中的一个term 的boost值,更确切地说(but rather),多个terms(multi terms)在一个查询里的表示形式(represent as)是多个TermQuery对象,所以查询里的一个term的boost值的访问是通过调用子查询(sub-query)的getBoost()方法实现的。
6. norm(t,d) 是提炼取得(encapsulate)一小部分boost值(在索引时间)和长度因子(length factor):
ú document boost – 在添加文档到索引之前通过调用doc.setBoost()来设置。
ú Field boost – 在添加Field到文档之前通过调用field.setBoost()来设置。
ú lengthNorm(field) – 在文档添加到索引的时候,根据(in accordance with)文档中该field的tokens数目计算得出,所以更短(shorter)的field会贡献更多的分数。lengthNorm是在索引的时候起作用,由Similarity类计算得出。
当一篇文档被添加到索引的时候,所有上面计算出的因子将相乘起来(multiplied)。如果文档拥有多个相同名字的fields(multiple fields with same name),所有这些fields的boost值也会被一起相乘起来(multiplied together):
然而norm数值的结果在被存储(stored)之前被编码成(encoded as)一个单独的字节(single byte)。在检索的时候,这个norm字节值从索引目录(index directory)中读取出来,并解码回(decoded back)一个norm浮点数值(float value)。这个编/解码(encoding/decoding)行为,会缩减(reduce)索引的大小(index size),这得自于(come with)精度损耗的代价(price of precision loss)- 它不保证decode(encode(x))=x,举例来说decode(encode(0.89))=0.75。还有需要注意的是,检索的时候再修改评分(scoring)的这个norm部分已近太迟了,例如,为检索使用不同的Similarity
2009年3月19日星期四
hadoop:"java.net.UnknownHostException: unknown host"解决办法
启动hadoop之后,查看datanode上的tasktracker日志时,发现有“java.net.UnknownHostException: unknown host”异常。
解决办法:在datanode机器的/etc/hosts中添加namenode 的信息:172.16.100.1 hostname of namenode.
解决办法:在datanode机器的/etc/hosts中添加namenode 的信息:172.16.100.1 hostname of namenode.
hadoop:“could only be replicated to 0 nodes, instead of 1” 解决办法
1. 检测当前用户的权限,保证对dfs.name.dir,dfs.data.dir,hadoop.tmp.dir等都有可读可写的权限;
2. 重新format namenode。
我的错误在于,初始建立上述三个目录时使用的是root权限,但后面改为了user权限,虽然user权限也设定了很高,启动hadoop时也没有任何错误,但是在运行hadoop dfs -put时就会报错。删除上述几个目录,并重新mkdir之后,再format namenode就没有报错了。
2. 重新format namenode。
我的错误在于,初始建立上述三个目录时使用的是root权限,但后面改为了user权限,虽然user权限也设定了很高,启动hadoop时也没有任何错误,但是在运行hadoop dfs -put时就会报错。删除上述几个目录,并重新mkdir之后,再format namenode就没有报错了。
2009年3月18日星期三
hadoop:Exception in thread "main" java.lang.UnsupportedClassVersionError: Bad version number in .class file
调用bin/start-all.sh启动hadoop时,可能出现Exception in thread "main" java.lang.UnsupportedClassVersionError: Bad version number in .class file错误。
解决方法:
在conf/hadoop-env.sh文件中,修改JAVA_HOME设置:export JAVA_HOME=/usr/java/jdk1.6.0_11。
hadoop-0.19版本之上,最好使用jdk1.6,不然还是会有问题。
解决方法:
在conf/hadoop-env.sh文件中,修改JAVA_HOME设置:export JAVA_HOME=/usr/java/jdk1.6.0_11。
hadoop-0.19版本之上,最好使用jdk1.6,不然还是会有问题。
2009年3月15日星期日
分析hadoop运行的日志
我在MapReduce的过程中,用system.out.print打印了一条信息,本机测试中是能够看到的,但是在hadoop环境中运行时,要在logs/userlogs中才可看到。
logs/userlogs下的目录结构如下:
drwxr-xr-x 2 root root 4096 Mar 16 13:50 attempt_200903161347_0001_m_000000_0
drwxr-xr-x 2 root root 4096 Mar 16 13:50 attempt_200903161347_0001_m_000001_0
drwxr-xr-x 2 root root 4096 Mar 16 13:50 attempt_200903161347_0001_m_000002_0
drwxr-xr-x 2 root root 4096 Mar 16 13:50 attempt_200903161347_0001_r_000000_0
drwxr-xr-x 2 root root 4096 Mar 16 13:50 attempt_200903161347_0002_m_000000_0
drwxr-xr-x 2 root root 4096 Mar 16 13:50 attempt_200903161347_0002_m_000001_0
drwxr-xr-x 2 root root 4096 Mar 16 13:50 attempt_200903161347_0002_m_000002_0
drwxr-xr-x 2 root root 4096 Mar 16 13:50 attempt_200903161347_0002_m_000003_0
drwxr-xr-x 2 root root 4096 Mar 16 13:50 attempt_200903161347_0002_r_000000_0
其中每个part文件夹中都含有log.index, stderr,stdout,syslog日志文件,其中log.index是统计信息,stderr是错误信息,stdout是标准输出信息,syslog是log信息了。
也许有一种方法可以将stderr, stdout, syslog集成在hadoop运行时一起输出,方便查看。等待下次实验。
logs/userlogs下的目录结构如下:
drwxr-xr-x 2 root root 4096 Mar 16 13:50 attempt_200903161347_0001_m_000000_0
drwxr-xr-x 2 root root 4096 Mar 16 13:50 attempt_200903161347_0001_m_000001_0
drwxr-xr-x 2 root root 4096 Mar 16 13:50 attempt_200903161347_0001_m_000002_0
drwxr-xr-x 2 root root 4096 Mar 16 13:50 attempt_200903161347_0001_r_000000_0
drwxr-xr-x 2 root root 4096 Mar 16 13:50 attempt_200903161347_0002_m_000000_0
drwxr-xr-x 2 root root 4096 Mar 16 13:50 attempt_200903161347_0002_m_000001_0
drwxr-xr-x 2 root root 4096 Mar 16 13:50 attempt_200903161347_0002_m_000002_0
drwxr-xr-x 2 root root 4096 Mar 16 13:50 attempt_200903161347_0002_m_000003_0
drwxr-xr-x 2 root root 4096 Mar 16 13:50 attempt_200903161347_0002_r_000000_0
其中每个part文件夹中都含有log.index, stderr,stdout,syslog日志文件,其中log.index是统计信息,stderr是错误信息,stdout是标准输出信息,syslog是log信息了。
也许有一种方法可以将stderr, stdout, syslog集成在hadoop运行时一起输出,方便查看。等待下次实验。
2009年3月12日星期四
hadoop基本命令整理
启动namenode&datanode命令: bin/start-all.sh
查看hadoop文件列表:hadoop dfs -ls
查看hadoop文件内容: hadoop dfs -cat xxx.txt
从local上传到hadoop:hadoop dfs -put src dest
从hadoop下载文件到本地:hadoop dfs -get src dest
删除hadoop的文件:hadoop dfs -rm xxx.txt
删除hadoop的文件夹:hadoop dfs -rmr input/
执行某个jar中的某个函数:hadoop jar hadooptest.jar WordCount
关闭命令:bin/stop-all.sh
格式化namenode: hadoop namenode -format
查看hadoop文件列表:hadoop dfs -ls
查看hadoop文件内容: hadoop dfs -cat xxx.txt
从local上传到hadoop:hadoop dfs -put src dest
从hadoop下载文件到本地:hadoop dfs -get src dest
删除hadoop的文件:hadoop dfs -rm xxx.txt
删除hadoop的文件夹:hadoop dfs -rmr input/
执行某个jar中的某个函数:hadoop jar hadooptest.jar WordCount
关闭命令:bin/stop-all.sh
格式化namenode: hadoop namenode -format
订阅:
评论 (Atom)


